
Scaling data systems: How we process millions of records with Python

Most people assume scaling data systems is just about performance.
It's not. Processing millions of records per hour with Python is very doable today. Between distributed compute frameworks, cheap object storage, and container orchestration, the tooling is already there. What matters is how you structure the system around the computation.
If the API tries to compute everything, the system becomes fragile. If the batch layer owns user-facing state, the product becomes hard to reason about. If the database stores every analytical artifact, it becomes a bottleneck. If object storage has no contract, every service quietly depends on undocumented paths.
In this post, I'll walk through how a real-world architecture like this is implemented in the project I lead, using Python (FastAPI), PySpark, Kafka, and Kubernetes.
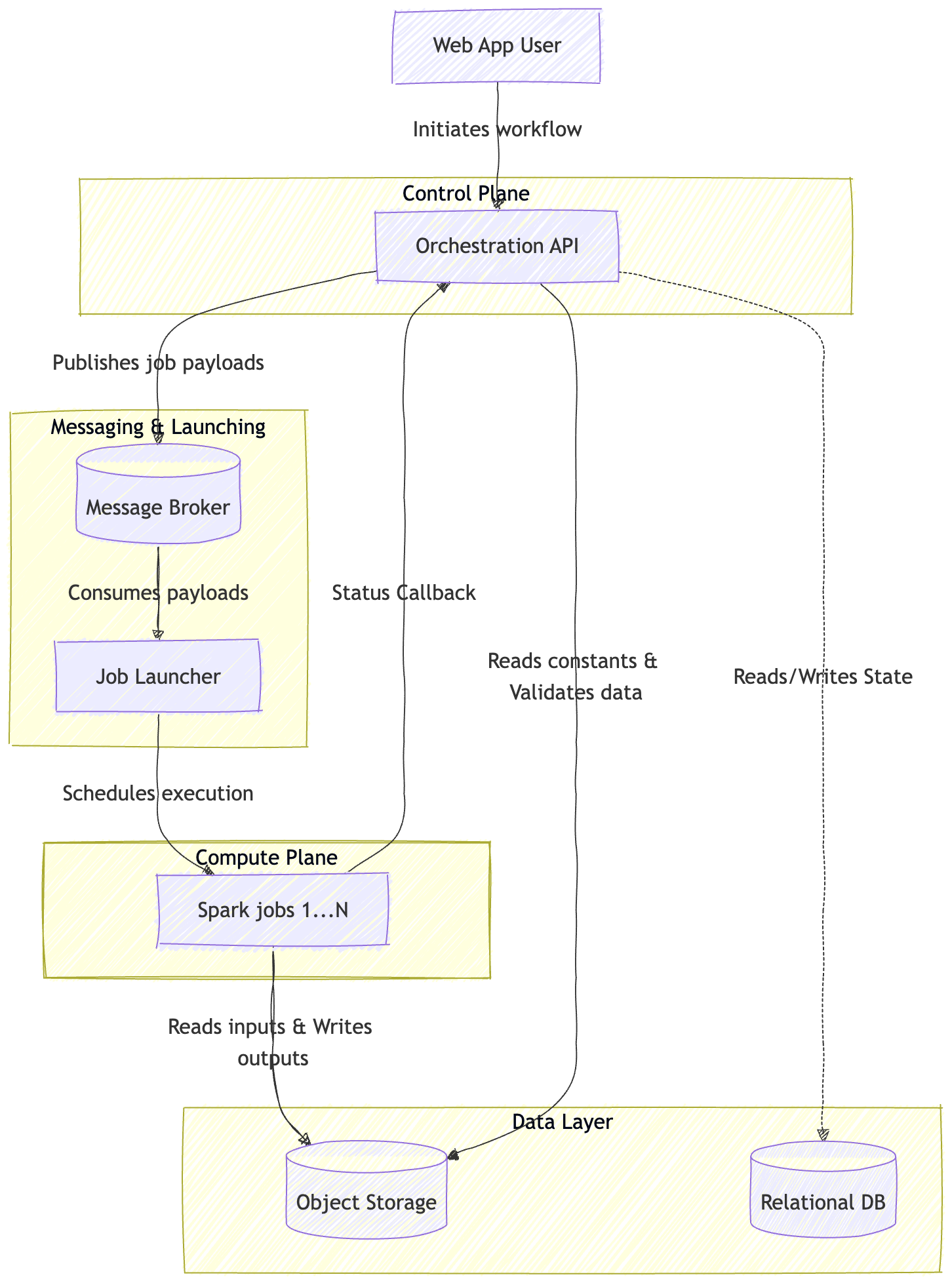
The architecture
We separate control plane from compute plane.
- The control plane handles APIs, state, and orchestration
- The compute plane executes distributed data processing jobs
- Object storage acts as the source of truth for all analytical data
Everything heavy happens asynchronously.
The flow
A typical request looks simple from the outside:
- A user triggers a calculation
- Results are eventually available
Under the hood, though, it's closer to this:
- The API validates the request and persists process metadata (PostgreSQL)
- A message is published to a queue (we use Kafka, but any queue service
will do) with CLI-like arguments:
- entity identifier
- data version
- action to execute
- callback URL
- A launcher service consumes the message and maps the action to:
- a Spark image
- a resource profile (driver/executors)
- The launcher creates a Spark job (via Kubernetes)
- The job:
- reads input datasets (Parquet) from object storage
- applies transformations (PySpark pipelines)
- writes outputs back to object storage
- The job calls back into the orchestration API with status updates
We can visualize it in this simplified diagram:
What makes it easy to scale
A critical separation in this architecture:
Orchestration layer
- Tracks processes and subprocesses
- Handles multi-tenant context
- Validates inputs (e.g., data availability in storage)
- Publishes jobs to Kafka
- Consolidates status via callbacks
Execution layer (Spark jobs)
- Stateless, short-lived
- ETL (Extract → Transform → Load)
- Report status via callbacks
So the API layer is strictly I/O bound. Heavy computation happens in distributed Spark jobs that can be easily replicated horizontally.
That's what allows the system to scale when processing large volumes of data.
Message-driven execution
All compute is triggered through a simple message contract, which keeps the launcher generic:
- It doesn’t need business logic
- It only maps actions → execution configuration
Data model: object storage as the source of truth
Large analytical data does not belong in the relational database.
PostgreSQL is excellent for process metadata, statuses, users, permissions, and audit records. It is not where you want to store millions of transformed rows, large Parquet datasets, generated CSV archives, and historical snapshots.
For analytical artifacts, the system uses S3-compatible object storage with a deterministic layout:
{entity_id}/{data_version}/...
Each version represents an immutable snapshot of processed data.
This gives us four important properties:
- Immutability (each version is a snapshot)
- Reproducibility (you can rerun computations on the same snapshot)
- Isolation (new runs don't overwrite old data)
- Scalability (no database overload with large payloads)
The trade-off is that storage paths become a shared API. If multiple services depend on the same layout, that layout must be documented, tested, and treated as a contract.
Why this architecture works
This setup works well because:
- APIs stay fast
- compute scales horizontally via Spark + Kubernetes
- large data never touches relational databases
- orchestration is explicit and observable
- services are loosely coupled via storage + messaging
Having that in place, we don't need to fight the system as it grows, we can just let it expand along the lines it was designed for.
In a future post, I will cover where this architecture starts to break, and why performance is usually not the first problem.